Architecture
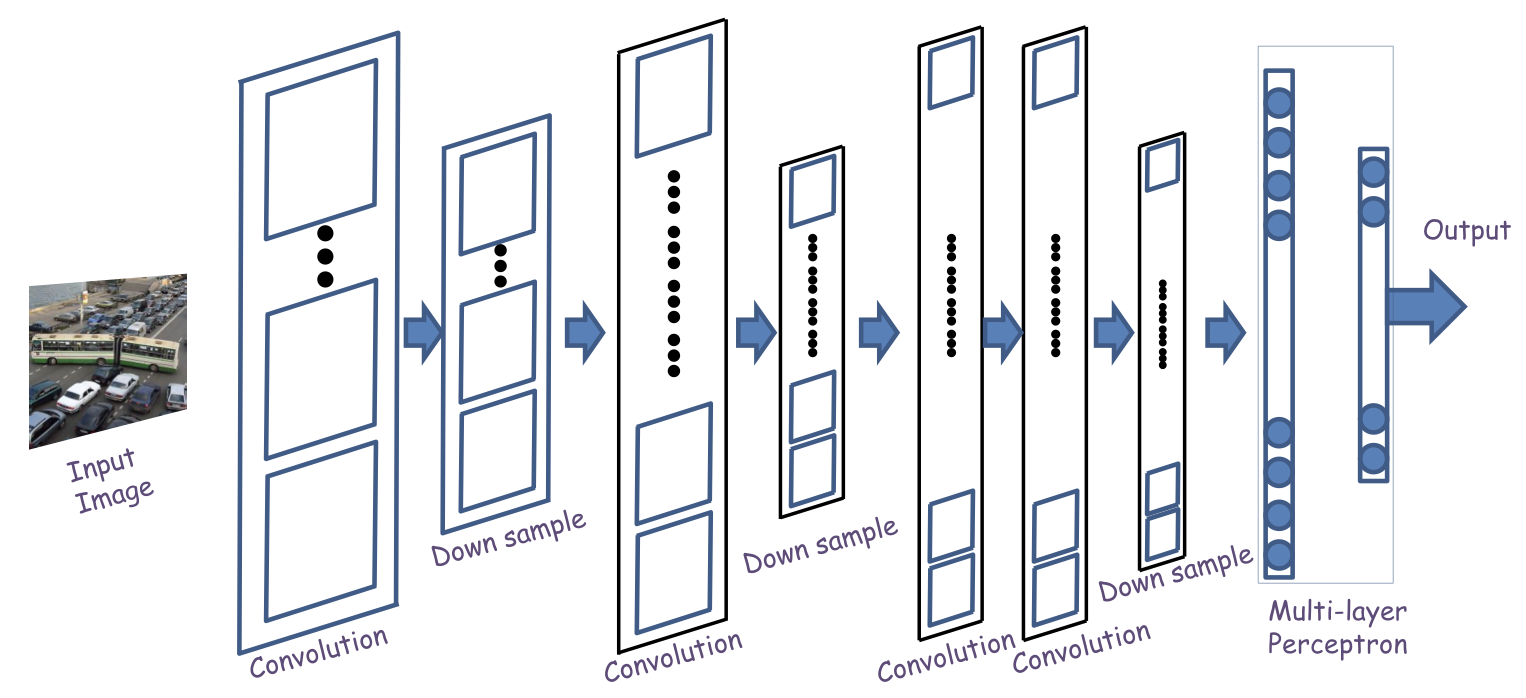
- A convolutional neural network comprises “convolutional” and “downsampling ” layers
- Convolutional layers comprise neurons that scan their input for patterns
- Downsampling layers perform max operations on groups of outputs from the convolutional layers
- Perform on individual map
- For reduce the number of parameters
- The two may occur in any sequence, but typically they alternate
- Followed by an MLP with one or more layers
A convolutional layer
- Each activation map has two components
- An affine map, obtained by convolution over maps in the previous layer
- Each affine map has, associated with it, a learnable filter
- An activation that operates on the output of the convolution
- What is a convolution
- Scanning an image with a “filter”
- Equivalent to scanning with an MLP
- Weights
- size of the filter × no. of maps in previous layer
- Size
- Image size: N×N
- Filter: M×M
- Stride: S
- Output size = ⌊(N−M)/S⌋+1
- Jargon
- Filters are often called “Kernels”
- The outputs of individual filters are called “channels”
Notion
- Each convolution layer maintains the size of the image
- With appropriate zero padding
- If performed without zero padding it will decrease the size of the input
- Each convolution layer may increase the number of maps from the previous layer
- Depends on the number of filters
- Each pooling layer with hop D decreases the size of the maps by a factor of D
- Filters within a layer must all be the same size, but sizes may vary with layer
- Similarly for pooling, D may vary with layer
- In general the number of convolutional filters increases with layers
- Because the patterns gets more complex, hence larger combinations of patterns to capture
- Training is as in the case of the regular MLP
- The only difference is in the structure of the network